Awalnya, tulisan ini dibuat untuk menunjang modul Mata Kuliah Praktikum Statistik Industri di Program Studi Teknik Industri, Universitas Mercu Buana Jakarta. Namun belakangan, permintaan tidak hanya datang dari peserta praktikum, tapi juga dari teman-teman yang sedang mengerjakan Tugas Akhir/ Skripsi. Saya berpikir: mungkin di luar sana, ada banyak orang yang membutuhkan tulisan ini.
Adapun beberapa hal yang dibutuhkan untuk analisis regresi dalam tulisan ini adalah:
- Seperangkat komputer + sistem operasi + software SPSS. Dalam tulisan ini, saya menggunakan SPSS 14.0 for Windows Evaluation Version.
- Pengetahuan entry data pada SPSS, lihat posting berjudul Dasar-Dasar SPSS.
- Tabel distribusi F (di buku-buku statistik) untuk F-test.
Sebelum masuk aplikasi SPSS, ada baiknya kita memahami analisis regresi. Selanjutnya akan diberikan contoh ilustrasi sederhana dan nyata untuk memahami analisis regresi.
A. Memahami Analisis Regresi
Ketika saya menanyakan harga sebuah perangkat komputer di toko komputer WTC Serpong, ternyata harga barang tersebut sekarang (November 2008) jauh lebih mahal dari bulan-bulan lalu, tanpa saya menanyakan kenapa harganya naik, sang penjaga toko langsung bilang: “dollar sekarang naik, Mas…!”. Di sini saya mengambil kesimpulan bahwa naik-turun harga barang dependent (bergantung) pada kurs dollar.
Dalam analisis regresi, variabel dependent (harga barang) dinotasikan dengan Y, sedang variabel independent (kurs dollar) dinotasikan dengan X.
Jika benar naik-turun harga barang (Y) hanya bergantung pada kurs dollar (jumlah X = 1) maka hubungannya dalam istilah statistik disebut: Linear Regression (regresi linear sederhana). Artinya harga barang ”berjalan–beriringan” (linear) dengan kurs dollar.
Namun, jika harga barang (Y) tidak saja bergantung pada kurs dollar (X1) tapi juga dengan variabel lain, misal: harga BBM (X2 , atau jumlah X = lebih dari 1) maka hubungannya dalam istilah statistik disebut: Multiple Linear Regression (regresi linear berganda). Artinya harga barang ”berjalan–beriringan” (linear) dengan kurs dollar dan harga BBM.
Yang menjadi pertanyaan sekarang, apakah benar harga barang linear dengan kurs dollar? (jangan-jangan itu hanya alasan sang penjaga toko). Untuk membuktikannya, kita harus mengumpulkan harga-harga barang dan nilai-nilai kurs dollar pada bulan-bulan lalu. Kemudian, kita melakukan Uji Keberartian dan Uji Signifikansi.
Uji Keberartian dapat dengan dua cara, yaitu:
- Scatterplot ‘diagram pencar’, di mana secara kasat mata akan tampak kecenderungan hubungan linear antara nilai-nilai statistik tersebut.
- Correlation Coefficient (R) dalam istilah SPSS, di mana kemungkinan ”kecenderungan hubungan tidak linear” didefinisikan apabila hasil R sama dengan nol, atau mendekati nol.
Uji Signifikansi adalah dengan t-Test, di mana nilai “t hitung” dibandingkan dengan nilai “t tabel”. Untuk pengujian terhadap Multiple Linear Regression dapat digunakan F-test.
Nah, apabila harga-harga barang bulan lalu (Y) dinyatakan “linear” dengan nilai-nilai kurs dollar bulan lalu (X), maka “benarlah” apa yang dibilang oleh si penjaga toko.
Dan apabila kita mengetahui (atau dapat meramalkan) nilai-nilai kurs dollar di bulan-bulan depan, maka kita dapat meramalkan harga-harga barang di bulan-bulan depan ( Ŷ atau Y-circumflex untuk membedakan dengan Y-biasa) dengan menggunakan persamaan:
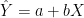
Koefisien a adalah nilai penaksir regresi (Y-intercept) dan koefisien b adalah nilai kemiringan (slope) garis regresi. Koefisien-koefisien ini merupakan bilangan-bilangan tetap yang harus kita cari dengan (n = jumlah observasi):
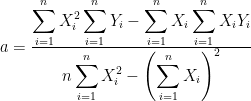
dan
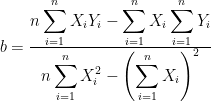
Sedangkan untuk persamaan Multiple Linear Regression adalah sebagai berikut:
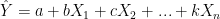
Analisis regresi bermanfaat untuk menghitung: (a) linear regression dan multiple linear regression, (b) asosiasi statistik beserta scatterplot, (c) diagnosa kolinearitas, (d) harga prediksi, dan (e) residual.
Jenis data yang cocok untuk analisis regresi adalah data rasio (baik untuk variabel dependent maupun independent). Namun dapat juga dengan data berbentuk kualitatif (kategori), tetapi harus dibantu dengan ”variabel boneka” (dummy variable). Contoh ”variabel boneka” adalah seperti pendefinisian value untuk variabel Gender, yang mana Laki-laki diberi kode angka “1” dan Perempuan diberi kode angka “2”.
Selanjutnya akan diberikan contoh aplikasi analisis regresi dalam SPSS, di mana yang menjadi penekanan pembahasan adalah pada saat Uji Keberartian dan Uji Signifikansi.
B. Contoh Aplikasi dalam SPSS
Contoh yang akan ditampilkan adalah analisis Multiple Linear Regression menggunakan SPSS, adapun kasusnya adalah sebagai berikut:
Harga suatu produk pada beberapa minggu mengalami fluktuasi, diperkirakan kondisi ini mempengaruhi tingkat penjualan/ tingkat daya beli konsumen. Di sisi lain banyaknya iklan telah mendongkrak tingkat penjualan. Bagaimana pengaruh harga produk dan iklan terhadap penjualan suatu produk?
Dari kondisi ini, penjualan dapat diartikan sebagai variabel dependent–yang dinotasikan dengan Y–terhadap variabel independent berupa harga dan iklan–yang dinotasikan dengan X.
Pengamatan akan dilakukan dengan mengambil secara random data 10 minggu penjualan, data berupa: (a) jumlah unit penjualan mingguan, (b) harga rupiah produk pada minggu bersangkutan, dan (c) banyaknya iklan yang ditandai dengan besarnya rupiah biaya iklan yang dikeluarkan pada minggu bersangkutan.
Dari kasus di atas, didapatkan Data Jumlah Penjualan (Y), Data Harga Produk (X1), dan Data Biaya Iklan (X2) sebagai berikut:
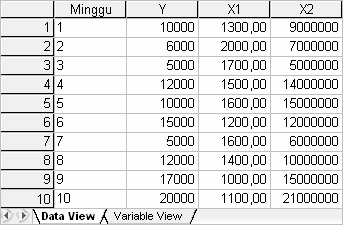
Setelah kita mengisi data pada SPSS Data Editor, ikuti langkah berikut:
Langkah ke-1: Klik menu Analyze –> Regression –> Linear

Langkah ke-2: Muncul dialog box Linear Regression.
- form Dependent, isi: variabel Y
- form Independent(s), isi: variabel X1 dan variabel X2

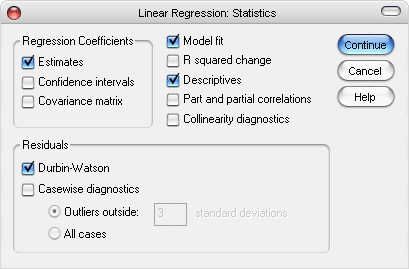
Langkah ke-3: Klik Statistics, muncul dialog box Linear Regression: Statistics, dalam hal ini dicentang: Estimates, Model fit, Descriptives, dan Durbin-Watson.
Kemudian klik Continue, untuk kembali ke dialog box Linear Regression.
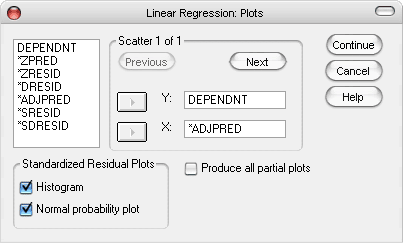
Langkah ke-4: Pada dialog box Linear Regression, klik Plots, muncul dialog box Linear Regression: Plots
- form Y axis, masukkan: DEPENDNT, artinya mendaftarkan variable dependent sebagai sumbu Y.
- form X axis, masukkan: ADJPRED, artinya mendaftarkan harga prediktor yang disesuaikan sebagai sumbu X.
- Centang juga: Histogram dan Normal probability plot.
- Kemudian klik Continue, untuk kembali ke dialog box Linear Regression.
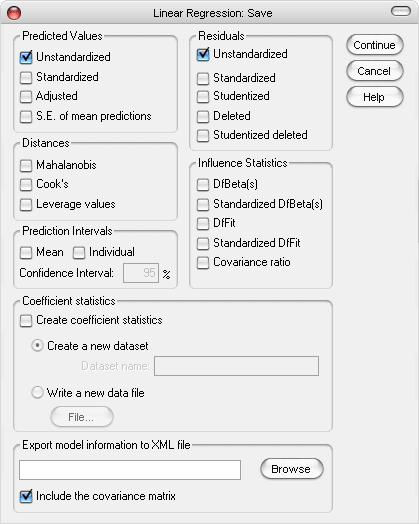
Langkah ke-5: Pada dialog box Linear Regression, klik Save.
Muncul dialog box Linear Regression: Save, pilih Unstandardized pada form Predicted Values dan form Residuals.
Kemudian klik Continue, untuk kembali ke dialog box Linear Regression.
Langkah ke-6: Pada dialog box Linear Regression, klik Options.
Muncul dialog box Linear Regression: Option, lalu klik saja Continue (berarti memilih setting default), dan kembali ke dialog box Linear Regression.
Langkah ke-7: Terakhir pada dialog box Linear Regression, klik OK.
Hasil lengkap SPSS dijadikan dalam satu file output dengan tersusun rapi sesuai dengan ketentuan yang dikehendaki di atas.
C. Hasil Analisis Regresi
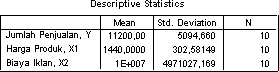
1. Descriptive Statistics
Hasil analisis data deskriptif di bawah merupakan hasil dari pemilihan check box Descriptive pada dialog box Statistics. Didapatkan nilai rata-rata serta standar deviasi untuk semua variabel, baik independent maupun dependent.
2. Matriks Koefisien Korelasi
Matriks Koefisien Korelasi (Pearson Correlations) juga didapat dari pilihan Descriptive pada dialog box Statistics. Kita dapat melihat koefisien korelasi antar semua variabel.
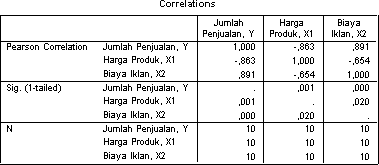
Pada matriks korelasi tersebut, didapatkan angka signifikansi untuk hubungan antar seluruh variabel independent dengan variabel dependent bernilai di bawah 0,05 (<0,05), sehingga dapat disimpulkan bahwa memang terdapat hubungan yang signifikan dan korelasi yang erat antara semua variabel independent dengan variabel dependent.
3. Variabel Entered/Removed
Hasil variabel Enter/Removed merupakan penentuan pilihan Enter (default) pada form Method, dialog box Option.

4. Model Summary
Pada bagian ini terdapat nilai koefisien determinasi R-Square = 0.932 (93,2%). Ini menunjukkan bahwa sebesar 93,2% variasi variabel dependent (Y) dapat dijelaskan oleh 2 variabel independent (X1 dan X2), artinya pengaruh variabel independen terhadap perubahan variabel dependen adalah 93,2%, sedangkan sisanya sebesar 6,8% dipengaruhi oleh variabel lain selain variabel independen X1 dan X2.

5. Anova
Pada bagian ini ditampilkan tabel analisis varian (Anova). Dari tabel di bawah didapat nilai F = 47,917 yang dapat digunakan untuk melakukan uji hipotesis atau F-test dalam memprediksi kontribusi variabel-variabel independent (X1 dan X2) terhadap variabel dependent (Y).

Hypothesis:
H0: β1 = β2 = 0
H1: Minimal satu dari dua variabel tidak sama dengan nol
Dengan menentukan level of significant = 5% (0,05) dan degree of freedom untuk df1 = 2 dan df2 = 7, maka didapat dari tabel (dalam buku statistik) F-tabel = 4,74.
Oleh karena F-hitung = 47,917 > F-tabel (0,05) = 4,74, maka H0 ditolak dan H1 diterima. Kesimpulannya, bahwa variabel independent (X1 dan X2) dengan signifikan memberikan kontribusi terhadap variabel dependent.
6. Coefficients
Pada bagian ini ditampilkan nilai koefisien regresi (lihat: nilai-nilai pada kolom B pada Unstandardized Coefficients di bawah ini) sehingga terbentuk persamaan regresi:
Ŷ = a + bX1 + cX2 = 16406,365 – 8,248X1 + 0,001X2

Pada bagian Unstandardized Coefficients ini ditampilkan juga Standard Error dari masing-masing variabel. Nilai pada kolom Beta, ditampilkan Z-score. Pada kolom berikutnya ditampilkan nilai t dari masing-masing variabel, yang dapat dimanfaatkan untuk menguji keberartian (t-Test) koefisien regresi yang didapatkan. Proses pengujiannya menyerupai F-test, yaitu “t hitung” dibandingkan dengan nilai “t tabel”.
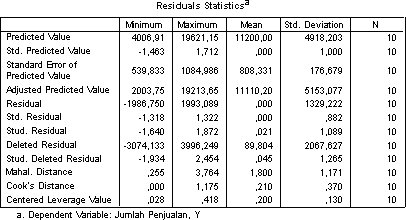
7. Residual Statistics
Pada bagian ini ditampilkan daftar hasil-hasil dari Residual Statistics.
8. Histogram

9. Normal Plot

10. Scatter Plot

Analisis regresi sangat membantu untuk mendapatkan bukti ilmiah dari suatu hubungan antara variabel-variabel sekaligus meramalkannya. Dalam ilmu eksakta hubungan antara variabel-variabel mudah dibuktikan karena sudah tegas dan diketahui, akan tetapi dalam kajian ilmu sosial, hubungan antara variabel-variabel pada umumnya masih belum tegas dan sering tidak diketahui. Oleh karena itu, SPSS (Statistical Product and Service Solution) pada awal berdirinya memiliki kepanjangan Statistical Package for the Social Science untuk menegaskan bahwa SPSS dapat membantu segala kesulitan dalam kajian ilmu sosial.
Rujukan:
Pasaribu, Amudi. (1983). Pengantar statistik (6th ed.). Jakarta: Ghalia Indonesia.
SPSS. (2005). SPSS (Version 14.0) [Computer software]. Chicago-Illinois: SPSS, Inc.

terima kasih atas semua ilmuny tentang olah data dengan SPSS,,,bagi saya sngat membantu karena saat ini sya sdang mngerjakan tesis dan slama ini sya begitu anti dengan SPSS karena belum terbiasa,,,sya mendapat banyak ilmu dri blog ini mulai dri dasar smpek bagian regresi linear,,,trnyta belajar SPSS tdak sehoror yg sya byangkn tpi menyenangkn dan sngat hemat waktu,,,sekali lagi terima kasih atas ilmuny smg tetap eksis dan bisa memberikan manfaat krpada orang bnyak
LikeLike
terima kasih atas kunjungannya
LikeLike
maaf mas eris saya mau tanya,
saya sedang belajar mengenai staistik menggunakan pspp untuk tugas ahir kuliah dan ketemu blognya mas. apa bisa diajarkan juga mengenai analisis regresi menggunakan pspp. terimakasih mas sebelumnya hehe
LikeLike
Di PSPP yg saya miliki hanya tersedia menu regresi linear, kurang lebih langkah-langkahnya sama dengan diatas
LikeLike
iya mas,punya saya juga psppnya cuma ada linier regresion. ga ada plot dan lain2. masih bingung nih mas cari2 referensi hehe
LikeLike
Alhamdulillah, terima kasih mas, sedikit banyak saya mendapat pencerahan dari blog anda. saya skrang pake spss 21
LikeLike
makasi ye atas blognya sangat bntu awak tok ujian ne
LikeLike
mas mau tanya…aku kan lagi ngitung bab4 nih tapi nilai r2 nya kecil cuman 25% aja. Sebenernya itu bagus atau nggak mas?
trus dosen ku menyarankan pake stepwise ,, udah baca tp tetep nggak mudeng caranya…bisa minta tolong dijelaskan nggak?
aku butuh banget jawabannya…terima kasih
LikeLike
makasih banyak atas informasinya. ini materi yang sedang saya cari. tapi saya ada pertanyaan nih. mohon jawabanya: kalo dilihat dari contoh yang diutarakan berarti multiple regresi ini bisa berfungsi pada kasus pengaruh beberapa independent variable terhadap dependent variable. Bagaimana jika independentnya satu tetapi dependentnya lebih dari satu. Apa kita bisa menilai dengan asumsi bahwa, independent variable mempengaruhi dependent variable yangmana? thanks untuk sharingnya..
LikeLike
pembelajaran yang sangat luar biasa. saya ingin minta tolong, bisakah dijelaskan langkah-langkah analisis tree / Classification and Regression Trees (CART) dengan menggunakan SPSS ?
saya sangat membutuhknannya, terima kasih.
LikeLike
Dear All,
Saat ini perusahaan kami sedang membutuhkan staf ahli yang ahli dalam bidang statistik dengan spesifikasi sebagai berikut :
Requirement :
– Deep knowledge in Statistics tools (SPSS, MatLab, etc.)
– Deep knowledge in Database or similar tools: PostgreSQL, SQL Server, and MySQL
– Familiar with Microsoft Office (Excel’s macro and formula, Word, Power Point,Visio)
– Understand the fundamentals of GSM/GPRS/EDGE/UMTS/HSPA network system
– Customer oriented, fast, conscientious, proactive, self driven and able to meet tight deadlines of project
– Familiar work with Telecom Vendor and Operators =
Scope of Work :
– Responsible to present micro cluster productivity class
– Responsible to track achievement of micro cluster performance
– Responsible to make statistic index and profiling achievement of micro cluster performance
– Responsible to maintain profile and statistic figure of performance, device (subs), and revenue related to network in micro cluster and in any cluster borders
– Responsible to perform statistic figure of performance related to promo & incident
– Responsible to support recommendation through matrix among performance, device (subs), revenue, and recharge share
– Responsible to support pre-analysis usage tendency and support performance forecast in any cluster borders
– Responsible to present report and pre analysis benchmark performance cellular operator and Telecommunication Industry trend analysis
Jika ada yang berminat untuk lowongan tersebut di atas, mohon dapat segera mengirimkan CV-nya ASAP ke recruitment@smartelco.co.id cc : chairul.fadli@yahoo.com, karena saat ini project sedang berlangsung. Terima kasih.
LikeLike
maaf mas eris saya mw tanya gimana memunculkan analyze tersebut sedangkan excel punya saya tahun 2007 dan yang ada data analisis toopalk, mohon bantuannya
LikeLike
Selamat siang pak, mau tanya uji yang cocok digunakan untuk membandingkan konten-konten, yang dibandingkan setelah disusun berdasarkan tingkat kepentingannya apa ya?
Misalnya : Survival kit untuk gunung meletus, isinya a,b,c,d,e,f,g,h,i,j. Survival kit untuk gempa bumi a,f,e,g,c,b,h,i,d. Nah untuk membandingkan antara isi survival kit gunung meletus dan gempa bumi tersebut apakah berbeda signifikan atau tidak bagaimana ya? Dan uji yang cocok digunakan dengan menggunakan SPSS apa ya? Terimakasih banyak 🙂
LikeLike
Reblogged this on Berbagi Dunia.
LikeLike
apa arti dari N itu mas?
LikeLike
Sangat membantu, terimakasih
LikeLike
mas eris, saya mau nanya.. sebenarnya apa sih yang mempengaruhi p-plot nya? misal ada data, 1/4 datanya agak menjauh dari garis diagonal.. sedangkan sisanya dekat dengan garis diagonal.. apakah data tersebut dapat dibilang normal? selain itu, saya juga lihat dari grafik histogram nya, bahwa tdk ada masalah dgn normalitas data tsb.. yg bermasalah hanya ada beberapa titik pada p-plot yg agak menjauh dari garis diagonal.. terima kasih mas eris 🙂
LikeLike
Piece of writing writing is also a fun, if you know afterward you can write or else
it is complex to write.
LikeLike
Bisa ga klo regressi itu independent variablenya ada 3?
Thankyou
LikeLike
Untuk questionnaire, Ada 9 questions utk IVariable, Dan 9 questions untuk DVaribable. Dgn jumlahin respondent 100. Cara masukin independent variable nya satu persatu pertama? Atau bagaimana? Mhn penjelasannya
LikeLike
Kang! R Squre saya 0,94, pengarunya sangat kecil kang, itu boleh tidak y?
Judull sya pengaruh kualitas pelayanan terhadap kepuasan konsumen
Menggunakan linear sederhanan
LikeLike
mau tanya kalau cara baca coefficient di metode stepwise karena ada include sm exclude, jadi nanti gmn penjelasan di pas bagian uji T ?
LikeLike
bagaimana caranya jika 2 variabel dependent dan 4 variabel independent?
LikeLike